
Bloom Filter(布隆过滤器)是一种空间利用很高的数据结构,使用一个数据来表示一个集合,用于判断一个元素是否存在于这个集合中。但是也有妥协:在判断一个元素是否属于该集合时有可能会误判(false positive),故不适合于"零错误"的场景,在能够容忍低错误率的场合下,可以通过极少的错误来换取较高的存储空间利用率。google的Guava中就有
BloomFilter这个类。一个比较常见的应用是缓解Redis等缓存中缓存击穿的问题。
参考学习
CSDN上有两篇很不错的学习文章,一篇详细的讲解了原理,一篇给出了一个java版的简单示意demo。本文主要是对这两篇的工作进行整理、总结、补充和学习。
原理学习:(96条消息) Bloom Filter概念和原理_jiaomeng-CSDN博客_bloom filter
demo:(96条消息) 布隆过滤器原理(小白都能看懂的demo)_成都彭于晏的博客-CSDN博客
实用学习:牛逼哄哄的布隆过滤器,到底有什么用? - Java技术栈 - 博客园 (cnblogs.com)
wiki学习:Bloom filter - Wikipedia
概念及原理
下面是wiki对布隆过滤器的介绍:
A Bloom filter is a space-efficient probabilistic data structure, conceived by Burton Howard Bloom in 1970, that is used to test whether an element is a member of a set.
False positive matches are possible, but false negatives are not - in other words, a query returns either "possibly in set" or "definitely not in set".
Elements can be added to the set, but not removed(though this can be addressed by counting Bloom filter variant); the more items added, the larger the probability of false positives.
怎么表示一个布隆过滤器呢?一个空的布隆过滤器是一个m bits的字节数组,其中所有的元素的值都为0。如下图所示:

然后我们定义k个不同的哈希函数,每一个哈希函数都会把输入映射到上面这个m bits的字节数组的每一个位置中,并将该位置为1。即: \[ \begin{align} \forall x,\ Bloom[Hash_i(x)]=1,\ where\ i \in [1, k]; \end{align} \] 需要注意的是,若一个位置已经被置为1了,那么后续的元素再次映射到该位置时则仍为1。假设k=3(3个哈希函数),我们将两个元素插入到过滤器中,结果如下图所示:
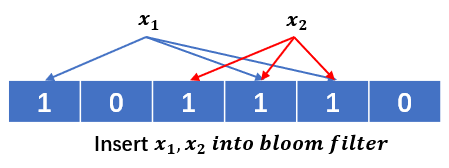
可以看到他们两个的哈希结果是有重叠的。
假设我们现在判断一个元素是否在集合中,道理是一样的,我们只需要对该元素进行k次哈希计算,若数组中对应下标的元素都为1,则认为该元素存在。但若有一个下标数值为0则该元素一定不存在。此外,布隆过滤器是不能删除元素的,因为你没有办法判断该数组中哪些1是该清除的,虽然你可以删除该元素的一个哈希结果位置的1(只要有一个哈希位置的结果为0则该元素不存在),但是有可能这个操作就顺带的把其他元素也删除了。
前面提到了布隆过滤器存在假阳性(false positive)的情况,我们设f为该布隆过滤器的假阳性的可能性,p为数组中0的比例,k为哈希函数的数量,m为布隆过滤器数组的长度,n为待映射的集合元素的数量。则最佳的(f最低)选取的哈希函数的数量k为:
\[ \begin{align} k\ =\ \frac{n}{m}ln2,\ 此时p=\frac{1}{2},\ 即布隆数组中0,1对半开 \end{align} \]
从这个结果中我们可以看出,要让布隆过滤器错误率较低,最好让该数组还有一半空着。且我们的哈希函数的数量至少是(n/m)的ln2倍。
同时,若要让错误率\(f\ \le \epsilon\),则m应至少取到下值: \[ \begin{align} m\ \ge\ n\log_2e\ \cdot\ \log_2(1/\epsilon) \end{align} \] 具体的推导计算过程可以去看CSDN推荐文章或者看wiki,均有详细运算过程,这里只说结论。
布隆过滤器Demo以及Guava中的案例
下面代码来自CSDN,做了部分修改,只供学习演示。
1 | import java.util.Arrays; |
下面我们写一个测试单元来看看他的效果,我们插入100万条数据,并使用其他不存在的100万条数据来进行测试:
1 | import org.junit.jupiter.api.AfterAll; |
实验结果:
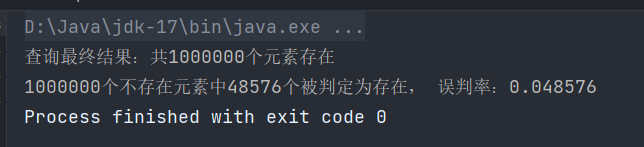
可以看到在100万条错误的测试数据中,有48576个假阳性样本,误判率为0.048,这个误判率还是很理想的。
当然,也有比较官方的包支持布隆过滤器,比如Google的Guava中就有该数据结构,只不过被标记为beta。我们同样使用Guava中的布隆过滤器进行实验:
1 | // Maven依赖: |
1 | import com.google.common.hash.BloomFilter; |
运行结果:
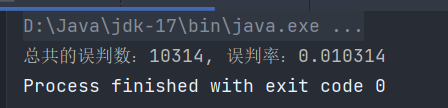
可以看到Google提供的布隆过滤器的效果更好,100万条错误数据中误判率为0.01。所以对于布隆过滤器而言,好的哈希函数是核心,这一点放到哪个与哈希相关的数据结构都是一样的。
特性及应用
特性
- 虽然布隆过滤器带来了一定的错误率,但是相较于其他数据结构(如自平衡二叉搜索树、字典树、哈希表、单链表、数组)有巨大的存储空间优势。上述的其他数据结构最少都需要将所有数据都保存到数据结构中(字符串类型中字典树除外,它可以减小将相同前缀的字符串的存储空间)。
布隆过滤器不需要存储全部数据,存储数据的工作需要另外一个部件进行(如下图所示,过滤器充当一个中间件),布隆过滤器只提供查询的功能(是不是很像Redis),比如wiki中的示意图:
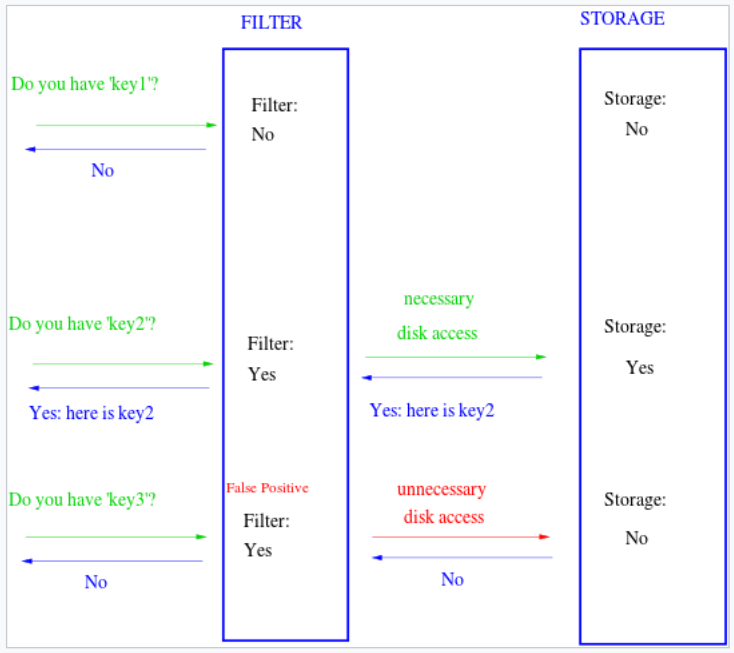
当然上述的架构中也有缺点:
- 假阳性(key3的请求)
- 布隆过滤器带来的更多的内存占用
wiki中描述布隆过滤器的该优势具体如下:
A Bloom filter with a 1% error and an optimal value of k, in contrast, requires only about 9.6 bits per element, regardless of the size of the elements. This advantage comes partly from its compactness, inherited from arrays, and partly from its probabilistic nature. The 1% false-positive rate can be reduced by a factor of ten by adding only about 4.8 bits per element.
相比之下,一个布隆过滤器在合适的k值的条件下,错误率仅为1%,且无论元素大小,每个元素只需要9.6个bit位。其优势来源于数组的紧凑性以及天然的概率特性。此外,这个1%的错误率在每个元素增加4.8个bit位的条件下,甚至还可以再减小10倍。
- 布隆过滤器的增加和查询操作的复杂度都是常数级--O(k),和存储的元素数量无关。这个属性是其他数据结构所不具备的,并且这k次查找是可以通过并行来减小时间的。
应用例子
以下应用例子均来自wiki,随便挑了几个。
- 内容交付商Akamai Technologies在服务器上使用布隆过滤器来有效减少磁盘工作负载并提高磁盘缓存命中率。
- Google Bigtable、Apache HBase、Apache Cassandra、PostgreSQL使用布隆过滤器来降低对不存在的数据的磁盘查找次数,避免了较大的磁盘开销,提高了数据库的查询效率。
- Google Chrome浏览器应用布隆过滤器来判别恶意的URL,若本地的布隆过滤器判断是阳性,则会对该完整的URL进行判断,并对用户进行警告。
- 比特币曾使用布隆过滤器来加速钱包的同步,后来其使用的布隆过滤器的实现发现了漏洞。
- 以太坊使用布隆过滤器来实现链上快速的日志查找。
布隆过滤器变种-Counting Bloom Filters
概念及原理
据wiki描述,大概有60种以上的布隆过滤器变种,这里由于我个人原因我只关注Counting
Bloom
Filters,该过滤器支持了原始布隆过滤器不支持的删除操作。该过滤器在论文Fan, Li; Cao, Pei; Almeida, Jussara; Broder, Andrei (2000), "Summary Cache: A Scalable Wide-Area Web Cache Sharing Protocol" , IEEE/ACM Transactions on Networking, 8 (3): 281–293, on 2017-09-22中提出。
怎么理解呢?在计数布隆过滤器中,我们把每一个数组的位置叫做bucket,将每一个数组的每一个位置由一个单一的bit位变为了多个比特的计数器(a multi-bit counter)。而普通的布隆过滤器你可以理解为一个bucket为1的计数布隆过滤器。
对于一个计数布隆过滤器:
- 当你添加一个元素时,就为该数组的对应下标的bucket的值增加1。
- 当你删除这个元素的时候则为这个bucket的值减1
- 当你查询一个元素的时候,若该元素对应下标的bucket的值均非0,则该元素存在
问题及替代品
- 计数布隆过滤器为了避免溢出问题,bucket的上限要足够大,通常取3到4bits,所以他使用的存储空间是普通布隆过滤器的3至4倍。
而在论文:
Pagh Anna; Pagh Rasmus; Rao S. Srinivasa (2005), "An optimal Bloom filter replacement" Proceedings of the Sixteenth Annual ACM-SIAM Symposium on Discrete Algorithms, pp. 823–829Fan, Bin; Andersen, Dave G.; Kaminsky, Michael; Mitzenmacher, Michael D.(2014), "Cuckoo filter: Practically better than Bloom", Proc. 10th ACM Int. Conf. Emerging Networking Experiments and Technologies (CoNEXT '14), pp. 75–88,
中所提出的过滤器也支持删除操作,且比普通过滤器使用的存储空间要小。
- 计数布隆过滤器的可扩展性受限,因为它的表(table)不可扩展,过滤器中存储的元素的最大数量必须提前预知,一旦前期设定好的阈值提前到达了,那么随着后续元素的不断插入,过滤器的错误率将不断提高。
而在论文:
Bonomi Flavio; Mitzenmacher Michael; Panigrahy Rina; Singh Sushil; Varghese George (2006), "An Improved Construction for Counting Bloom Filters", Algorithms – ESA 2006, 14th Annual European Symposium, 4168, pp. 684–695,中提出的过滤器可以避免可扩展性受限的问题,且仅大约使用计数过滤器一半的空间就可以实现相同的功能。Rottenstreich, Ori; Kanizo, Yossi; Keslassy, Isaac (2012), "The Variable-Increment Counting Bloom Filter", 31st Annual IEEE International Conference on Computer Communications, 2012, Infocom 2012, pp. 1880–1888中提出的过滤器中引入了一种基于可变增量的通用方法,显著降低了计数布隆过滤器及其变体的错误率,且仍然支持删除操作。不同的是插入元素时将递增一个哈希变量增量而不是一个单位增量,在查询元素时需要考虑计数器值的正确性,而不仅仅是数值。