本篇记录学习栈溢出、堆溢出的原理以及基本的内存布局
内存布局
首先这里讨论的内存布局有两种,一种是系统内存,一种是进程内存,二者对比图如下:
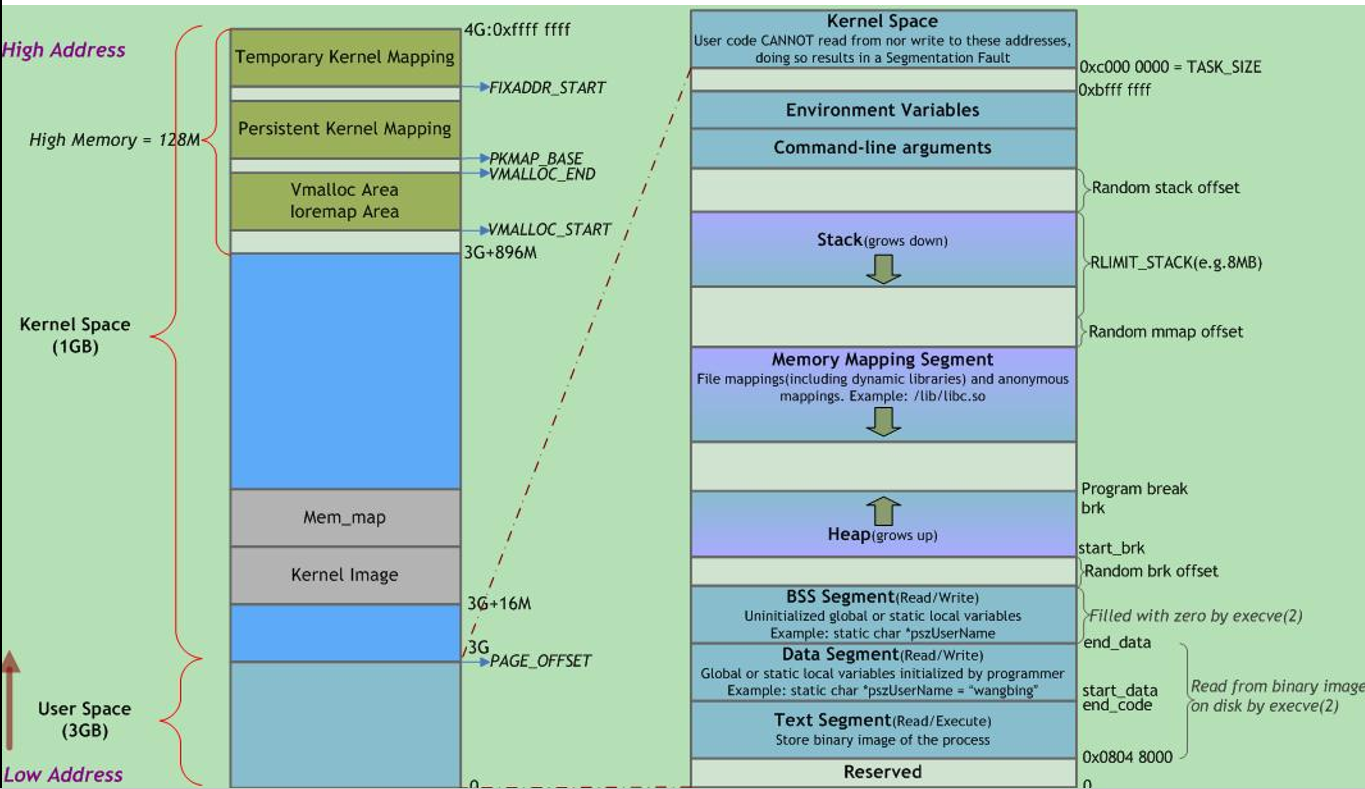
左边这个是系统的内存布局,从上到下地址减小,高地址的1G为系统内核空间,即保留部分;下面的3G大小为用户空间内存,这个布局是32位x86操作系统的布局,其他细节这里不考虑。右边的这一部分为用户空间的内存布局,其大小为3G,对应地址为0x00000000到0xbffffff。这一部分就是进程的内存空间了,我们下面只关注这一部分,如下图:
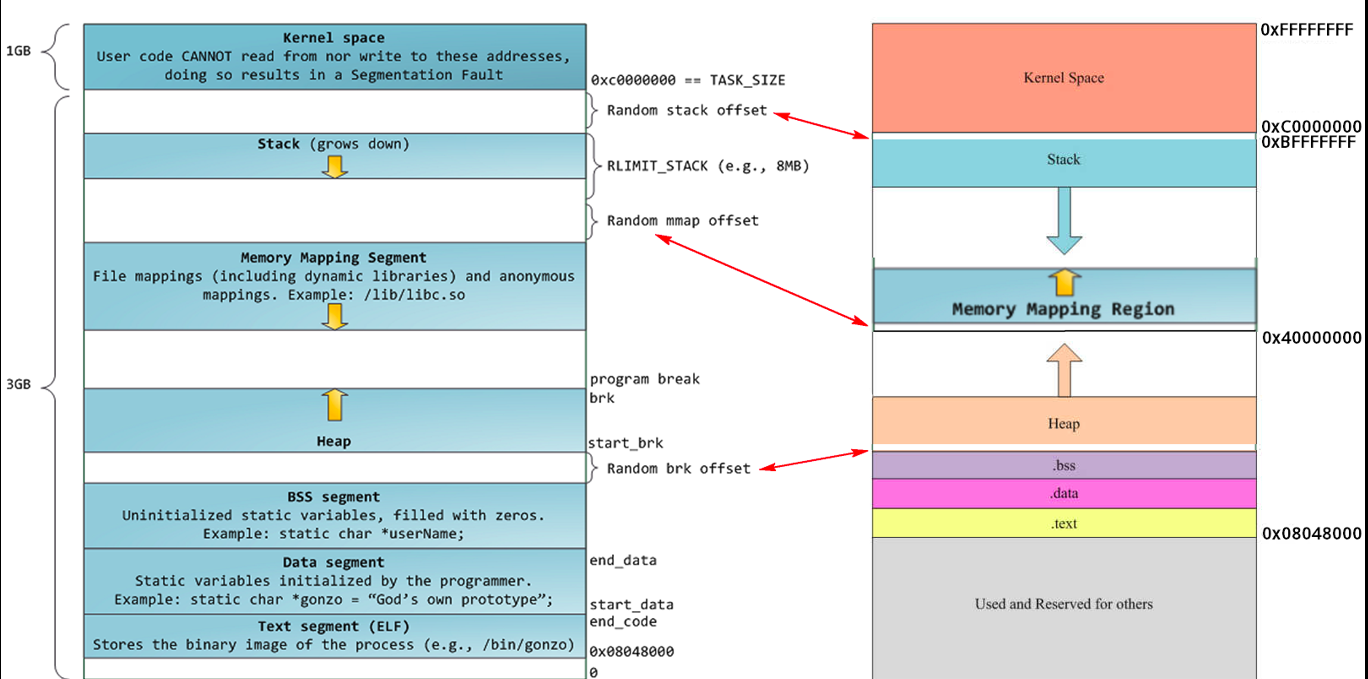
左侧就是进程内存了,最上面是内核空间,用户是不可以访问的。下面的部分主要部分有下面这几个:
- Stack : 栈,由高地址向低地址生长,常用于储存一些局部变量、函数参数值,由操作系统自动分配,使用的一级缓存。
- Memory Mapping Segment : 内存映射段,常用于链接一些共享连接库等。
- Heap :
堆,由低地址向高地址生长,常用于储存用户使用
malloc、new等函数或关键字开辟的单元,生命周期由垃圾回收算法来决定,使用的是二级缓存。 - BSS Segment :
Block Start By Symbol的缩写,用于储存一些未初始化的全局变量或赋值为0的全局变量。 - Data Segment : 数据段,用于储存一些已初始化的静态变量、全局变量等。
- Text Segment : 文本段,常用于储存可执行文件的二进制映像,只读。
在他们中间的空白是一些任意的偏移,即ASLR地址空间随机化的技术。
对于32位的操作系统而言,2^32次方也就是4G,也就是说每一个进程都有一个4G的虚拟地址空间的虚拟内存,但是实际上当然不可能给每一个进程都分配4G的物理内存,不管是内存资源珍贵的过去还是现在这都是不现实的,那么是如何实现的呢?
这里设计两个概念(虚拟页表,地址转换)和一个部件(MMU)。实际上系统给程序分配的是虚拟内存,在程序看来,这段虚拟内存是连续的,实际上这段虚拟内存是一部分在物理内存中,还有一部分在外部的磁盘储存设备上,用来进行数据交换。举一个例子的话,内存取证中,实际上进程的数据你不一定能导出,因为它可能存在与外部磁盘设备上,而你只有内存。
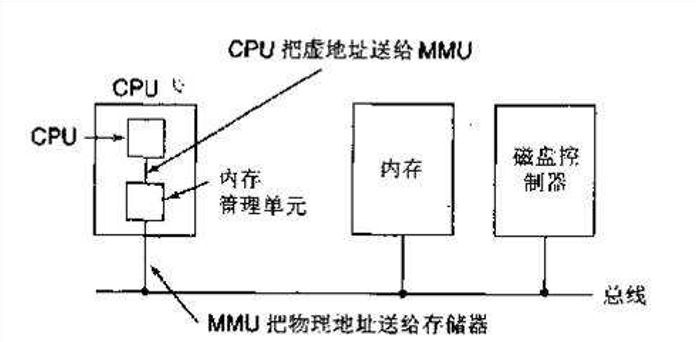
所以当程序需要访问某个地址数据时,需要进行一个地址转换的工作,这个工作由MMU(Memory Management Unity)完成,如图:
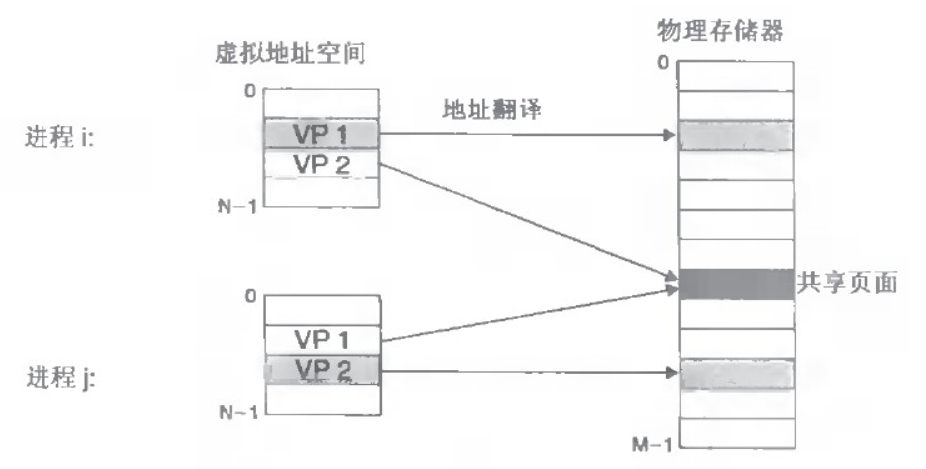
所以为了方便进行数据的查找以及空间的划分,虚拟页表就诞生了,简单来说,虚拟页表的工作是将虚拟内存中的地址映射到物理内存中,当CPU访问一个虚拟地址时,在内存中没有映射进对应的页,此时就会发生缺页异常,就会将虚拟内存中的数据通过MMU单元的翻译映射到物理内存中去,如下图所示(VP即Virtual Page,虚拟页),共享页面是一些如通用的共享库的共享数据。
这里注意一点,程序中的段,如.text,
.data等并不是在程序运行时就全部加载到物理内存的,而是只建立上述的虚拟页表,当需要这个数据,发生缺页错误的时候,才会将对应的数据映射到物理内存中供CPU使用。
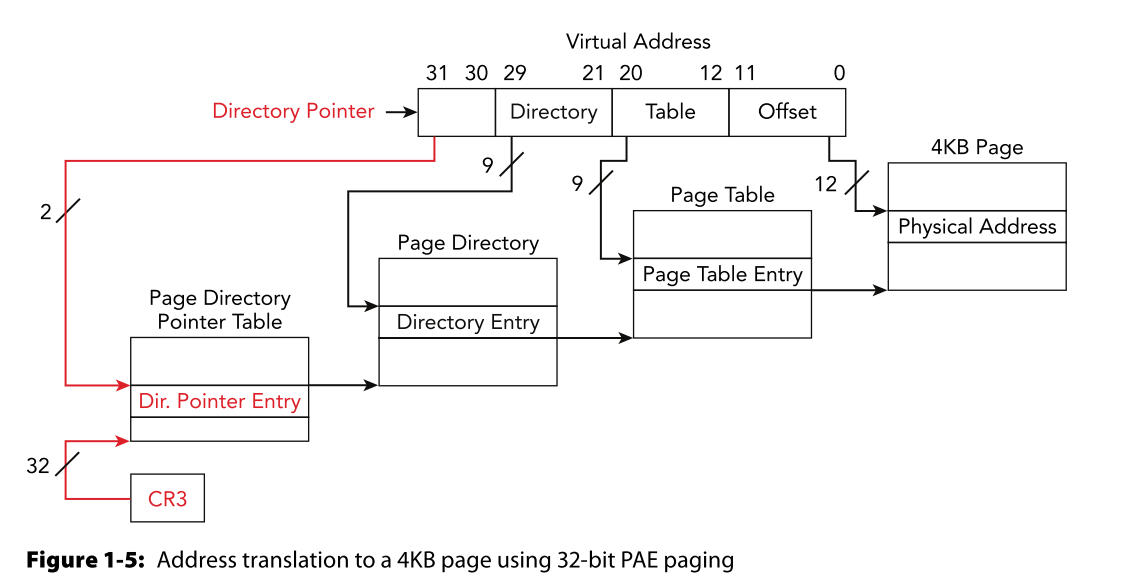
关于具体怎么寻址的问题,这里不做说明,这张图就可以看懂了(来源:The Art Of Memory Forensics)
下面通过一个实例来了解一下各个类型的数据都是分配在进程内存中具体哪一个部分的。
一个实例
1 |
|
在main函数中定义了一个int型变量,一个char数组,两个指针,其中一个使用malloc函数为其分配空间;另一个直接指向一个字符串,此外还有一个static关键字修饰的int型变量。在函数的外面有两个全局变量,一个是int型变量,另一个是未初始化的指针。
在IDA中查看main函数:
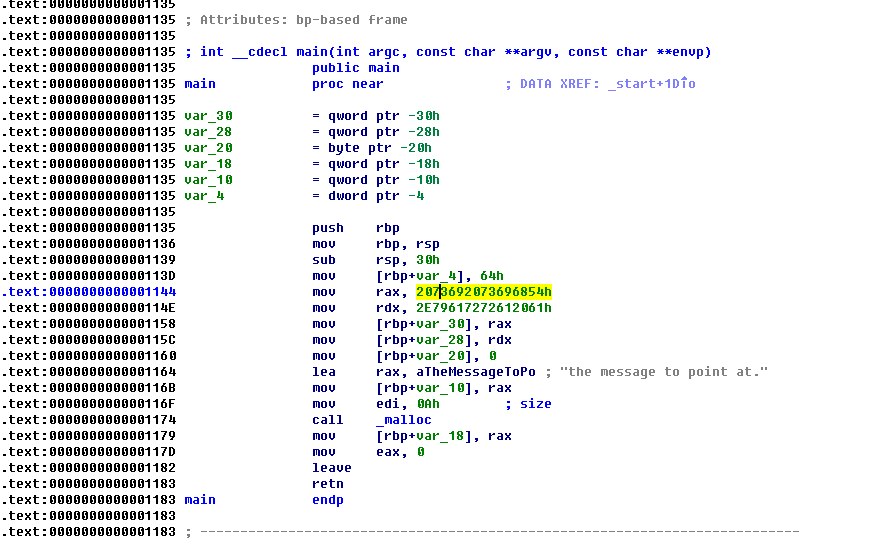
可以看到.text段基本就是我们代码的逻辑了,所以这里这个段内储存的是我们可执行文件的二进制映像。
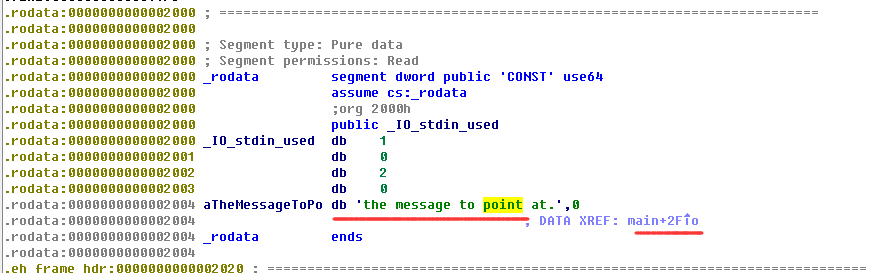
因为我们在main函数中定义了一个指向一个常量字符串的指针point2,可以看到它指向的数据处在.rodata(只读数据)段。
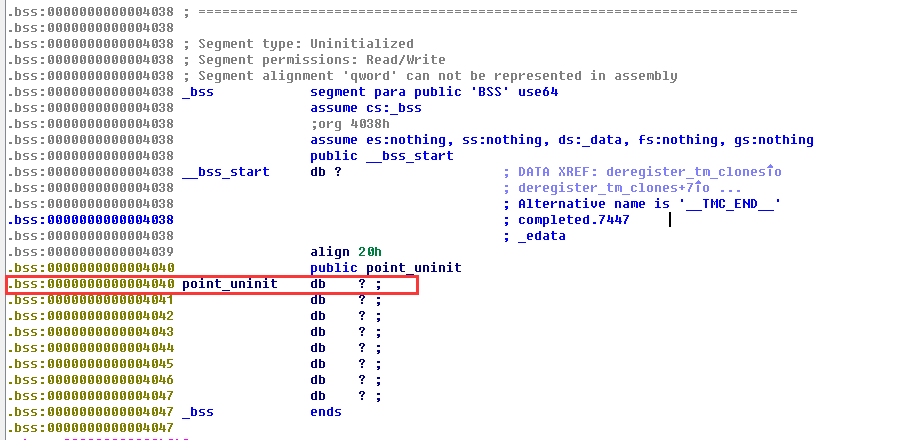
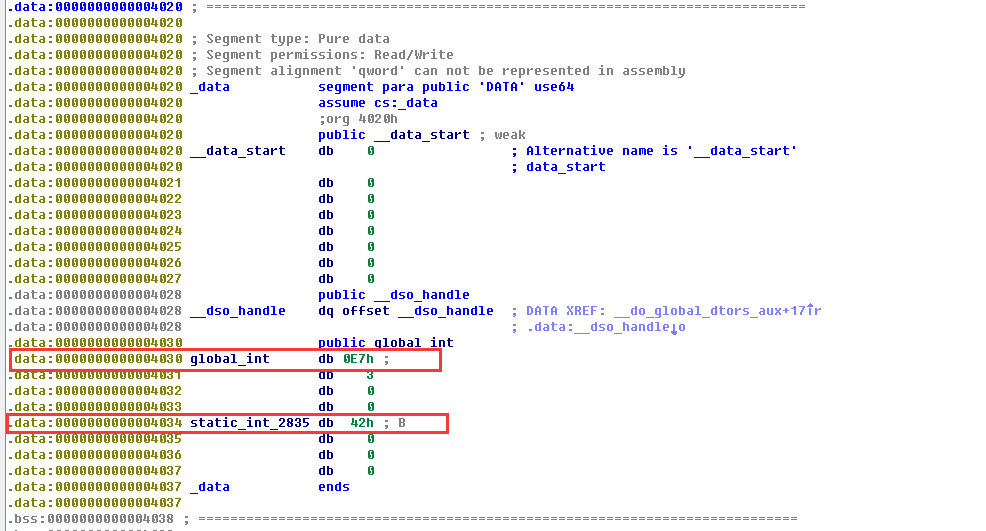
在.bss段可以看到我们没有初始化的全局变量char *point_uninit。而global_int变量同样是全局变量,因为赋予了初始值,所以在.data可以看到;同样main函数中因为使用了static关键字定义了一个常量,所以也可以看到:
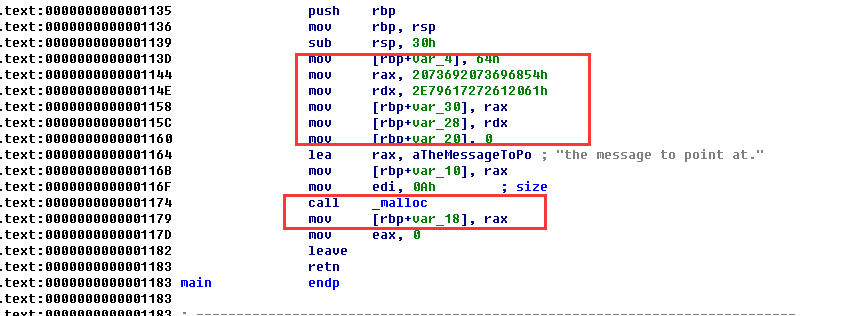
至于剩下的变量,除去使用malloc关键字分配的存在于堆上之外,其余都在栈上(都是通过rbp寄存器进行操作的),实际的数据只有程序运行起来的时候才会进行加载:
栈溢出原理
这部分的学习需要对汇编指令有一定的了解,不是说不了解不行,了解可以帮助你更好学习
栈溢出攻击主要是在代码逻辑存在漏洞的情况下(如没有检查用户的输入长度),将一个不合法的数据填入到了栈中,但是由于长度远远大于该变量的长度,导致超出范围的数据将比该变量的地址高的常量进行了覆盖,具体的实例可以看我的另一篇博客。这里只简单的用图来示意原理:
栈工作原理
首先了解一下栈的工作原理。栈存在的意义是什么?从数据结构的角度来看,栈是一种先进后出的效果,这样的逻辑特性与函数调用之间的关系是有相似之处的。假设有函数A,B,C,调用关系为A->B->C,假如我们用一个栈来记录这个调用过程的话,栈底当然是函数A,而栈顶则是函数C了。这只是一个很粗略的想法,函数当然需要参数,调用方要传入实参,被调用方要用形参来接收;除此之外我们还需要记载一下调用方调用函数时,代码执行到了什么位置等等。这些所有的信息,都需要使用栈来进行记录,而操作栈的则是一些寄存器和汇编指令。
其中最重要的两个寄 存器是ebp和esp(32位),ebp(extended base pointer),即扩展的基址指针寄存器,听名字就知道是干啥了的,esp(extended stack pointer),即扩展的栈顶指针寄存器。这两个寄存器是配对使用的,esp在扩展空间后会减小(栈是逆向生长的哈),但是ebp会始终指向栈的底部,为啥要指在底部不动?因为esp是变化的量,如果你要访问栈中的数据,当然是使用一个不变的量esp+偏移地址要方便的多。
当你要初始化一个局部变量的时候,esp指针就会向下开辟空间,再将你的数据移入,之后的访问会使用ebp+变量的大小进行访问。而当你要调用一个函数时,会进行以下步骤:
- 先将你的实参以从右到左的方式压入栈中
- 将下一条语句的地址压入栈中
- 将当前ebp压入栈中
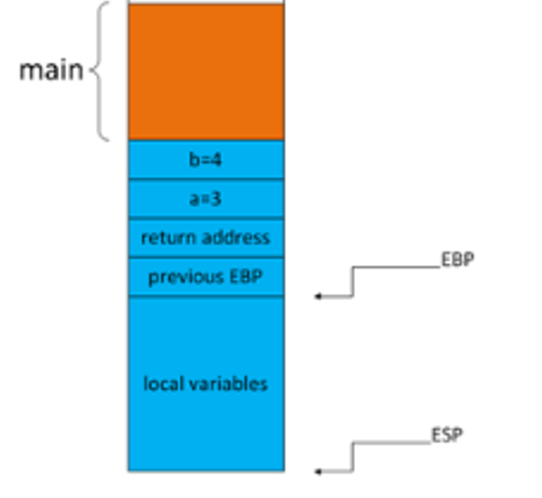
而当子函数执行完毕后,就会将子函数的esp重新指向子函数的ebp,再弹出ebp恢复父函数的ebp,接着弹出返回地址到eip继续执行父函数的代码。最终的结构大概是这样的(main函数中调用子函数foo(3, 4)):
栈溢出的危害
假如在上图的子函数中存在需要用户输入的变量而没有加以控制其大小,那么就是危险的。首先用户输入到栈中的变量是从低地址到高地址生长的,也就是下面图这样:

假如这个name数组的大小为10字节,如果你输入的是一个超过10字节的变量呢?在没有任何保护机制的情况下,就会向高地址生长,覆盖掉其他变量,覆盖掉ebp,甚至返回地址的值,这样就可以实现篡改其他只读变量或者函数返回地址来控制程序流程的目的,与之相关的技术层出不穷,当然现有的防护机制也是有的,如DEP保护,Canary金丝雀机制,ASLR机制,影子栈等等。
堆溢出原理
堆溢出危害
参考学习
https://blog.csdn.net/lvyibin890/article/details/82217193
https://blog.csdn.net/DLUTBruceZhang/article/details/9058583